Testing in Production: the hard parts
Author’s Note: Thanks, as ever, to Fred Hebert, for reading a draft of this post and making some sterling suggestions. This is the third installment in my series on testing distributed systems. The posts in this series are the following:
Testing Microservices, the sane way (published December 2017)
Testing in Production, the safe way (published March 2018)
Testing in Production: the hard parts (published in September 2019)
Testing in Production: the fate of state (published 2022)
There’s a fair bit of chatter about the virtues of testing in production these days. I’ve myself written about this topic over a year ago. This post isn’t so much of an argument as to why one should be testing in production (the previous posts linked above must’ve made a compelling enough case as to why testing in production is indispensable for certain kinds of systems) than an honest analysis of the challenges inherent in conducting these forms of tests.
Two of the hardest problems of testing in production are curtailing blast radius and dealing with state. In this post, I aim to explore the topic of curtailing blast radius in more detail. In a follow-up post titled Testing in Production: The Fate of State, I plan to explore the intricacies of testing stateful services in production.
Blast Radius
In early July 2019, Cloudflare had a 30 minute global outage that was caused due to a deploy of code that was meant to be “dark launched”.
Starting at 1342 UTC today we experienced a global outage across our network that resulted in visitors to Cloudflare-proxied domains being shown 502 errors (“Bad Gateway”). The cause of this outage was deployment of a single misconfigured rule within the Cloudflare Web Application Firewall (WAF) during a routine deployment of new Cloudflare WAF Managed rules.
The intent of these new rules was to improve the blocking of inline JavaScript that is used in attacks. These rules were being deployed in a simulated mode where issues are identified and logged by the new rule but no customer traffic is actually blocked so that we can measure false positive rates and ensure that the new rules do not cause problems when they are deployed into full production.
Unfortunately, one of these rules contained a regular expression that caused CPU to spike to 100% on our machines worldwide. This 100% CPU spike caused the 502 errors that our customers saw. At its worst traffic dropped by 82%.
One of the main incentives of testing in production is the fact that test code lives in the same environment as the production code serving user traffic. This helps build confidence that code that was tested in the production environment will behave similarly once it’s promoted to serve all user traffic. However, this happens to be a bit of a double-edged sword, in that this benefit can also be a massive risk vector.
When testing in production, the production environment is housing two tenants — a known good version and a new version that is potentially completely broken. In the worst case, this can take down the entirety of the production infrastructure, as it happened in the case of the Cloudflare incident, causing a user-visible outage. This is an inevitability of testing in production, unless one is shadowing the entirety of production traffic to a completely isolated parallel stack that mirrors production in every last way, something not often tenable due to the operational complexity in setting up such an environment and the attendant capex involved.
It’s important to note here that the goal of testing in production isn’t to completely circumvent code under test from causing any impact to the production environment. Rather, the goal of testing in production is to be able to detect problems that cannot be surfaced in pre-production testing early enough that a fully blown outage can be prevented from happening.
The best mindset to adopt when testing in production lies in accepting the reality that the test can either succeed or fail, and in the event of failure, it’s very likely there will be some impact to the production environment. It then follows that proactively thinking about the blast radius of the impact should the test fail becomes a sine qua non before conducting any such experiments in production.
In many respects, the best practices for safely testing in production are the same as the best practices for curtailing the blast radius of a system. Systems must be designed so that the failure domain is small and contained. Likewise, the path to the restoration of service must be a familiar and well-trodden one. With the production environment being ever changing, the only way to ensure that the path to service restoration is always a well-trodden one is by continually testing the restoration of a service.
To adapt what Sarah Jamie Lewis said to a distributed systems context: the whole point of [actual] distributed systems engineering is you assume you’re going to fail at some point in time and you design the system in such a way that the damage, at each point is minimized, that recovery is quick, and that the risk is acceptably balanced with cost. Werner Vogels wrote in a post titled 10 Lessons from 10 Years of Amazon Web Services:
We needed to build systems that embrace failure as a natural occurrence even if we did not know what the failure might be. Systems need to keep running even if the “house is on fire.” It is important to be able to manage pieces that are impacted without the need to take the overall system down. We’ve developed the fundamental skill of managing the “blast radius” of a failure occurrence such that the overall health of the system can be maintained.
Testing in production allows for the verification of the twin aspects of system design: if the test passes, it helps improve confidence in the robustness of the system, and if the test fails, one can end up exercising (and thereby testing!) mitigation strategies to restore the service back to health, which helps build confidence in the effectiveness of some subset of one’s disaster recovery plans. This ensures that service restoration is an effort undertaken regularly and not just during a widespread outage. In a manner of speaking, preparedness and general disaster recovery competence becomes a prerequisite (and not just something co-developed) when testing in production.
Prevention and Mitigation of Test Mishaps
AWS famously has a “Correction of Errors” template in their postmortem document, where engineers involved in the incident are required to answer the question “how could you cut the blast radius for a similar event in half?” In my experience, complex systems can and often do fail in unanticipated ways. Improving the resilience of such a service becomes an undertaking with ever-shifting goalposts.
That said, there are certain patterns that can help minimize the blast radius of a test that didn’t go according to plan. I have to underscore that these are just general guidelines; by no means are these definitive truths. Ultimately, as Rick Branson states:
Safe and Staged Deploys
Easily one of the most impactful areas of investment would be divorcing deploys from releases. These two posts [1] [2] explain the difference between a deploy and a release and why it becomes so important to delineate the two. In a nutshell:
Deployment is your team’s process for installing the new version of your service’s code on production infrastructure. When we say a new version of software is deployed, we mean it is running somewhere in your production infrastructure. That could be a newly spun-up EC2 instance on AWS, or a Docker container running in a pod in your data center’s Kubernetes cluster. Your software has started successfully, passed health checks, and is ready (you hope!) to handle production traffic, but may not actually be receiving any. This is an important point, so I’ll repeat it… Deployment need not expose customers to a new version of your service. Given this definition, deployment can be an almost zero-risk activity.
When we say a version of a service is released, we mean that it is responsible for serving production traffic. In verb form, releasing is the process of moving production traffic to the new version. Given this definition, all the risks we associate with shipping a new binary — outages, angry customers, snarky write-ups in The Register — are related to the release, not deployment, of new software.
Furthermore, building up a robust deploy-observe-release or rollback-observe-mitigate pipeline can go a long way toward reducing the risk profile of deployments. Having a good plan to be able to gradually shift traffic goes hand in hand with staged deploys. Continuous delivery tools like Spinnaker come with some form of support for such canary testing out of the box.
Next, rollouts need to be incremental. Netflix famously blogged about tips for high availability, and almost all of them pertain to staged deploys. Incremental rollouts should be the norm, not just for code but also (and more importantly) for configuration. A paper from Facebook from 2015 sheds light on how such a rollout might look like:
We safeguard configs in multiple ways. First, the configuration compiler automatically runs validators to verify invariants defined for configs. Second, a config change is treated the same as a code change and goes though the same rigorous code review process. Third, a config change that affects the frontend products automatically goes through continuous integration tests in a sandbox. Lastly, the automated canary testing tool rolls out a config change to production in a staged fashion, monitors the system health, and rolls back automatically in case of problems. A main hurdle we have to overcome is to reliably determine the health of numerous backend systems.
A large number of configuration related outages can be prevented if the process of delivering configuration were identical to the process of delivering of code. Push out a changeset to a small subset of the infrastructure, monitor the application and system metrics of the service in question and its immediate upstreams and downstreams (this is important!) to ensure everything looks good, before gradually rolling out the change more widely.
Staged deploy of stateless services is much easier than staged deploys of underlying stateful services like databases or core platform software. The follow-up article is entirely focused on testing stateful systems in production. As for testing platform software in production, if you happen to be testing the deploy of some component of a platform (like monitoring agents, sidecars, schedulers, scheduler agents and so on) atop which other services run, there might be other considerations at play. Are these deployments truly “immutable”? When testing in production, do updates happen “in-place” or do existing services require to be migrated off the old platform to the newly deployed version of the platform being tested? What is the impact of these migrations? What happens when the migration goes wrong — is there a way to migrate services back to the old version of the platform? What safety guarantees need to be provided to service owners? Are services designed so that they can withstand churn? Can services safely run using an old version and a new version at once, especially if there are backwards incompatible changes in the new version? How is the risk communicated with the service owners? What happens when service owners are deploying their services at the same time the platform change is being tested in production?
Again, these are hard sociotechnical problems with no one-size-fits-all solution. Pretending otherwise is naive at best and disingenuous at worst.
Quick Service Restoration
When practicing staged rollouts, it’s imperative to be able to mitigate the impact should something go awry before it can cause further failures upstream or trigger a chain of events that leads to a cascading failure. Service unavailability or degraded performance due to a test run in production does contribute to the “error budget” of a service (or whatever other heuristic is used to track SLOs over time). Too many mishaps when testing in production can burn through the error budget, allowing little leeway for scheduled maintenance and other operational contingencies that might require taking a service offline.
While some might argue that there’s no such thing as a “rollback”, for code changes of stateless services, reverting the change can (and often does) fix the problem, unless this change ended up poisoning the state of some upstream service, something which will be discussed in the upcoming post. Rolling back to a pre-built artifact can also be much faster than going through the build pipeline again, in which case “rolling back” might save additional delays in resolving incidents compared to “rolling forward”.
For core platform software or stateful services, rollbacks are more fraught with peril and uncertainty than it is for stateless services. In some rare cases, there indeed might be no such thing as a rollback. In certain other cases it might even be more preferable to run a buggy version of the platform and then fix the problem (called a “roll-forward”) than attempt a rollback. And of course, there exist hybrid strategies that “roll-forward” gradually. As Fred Hebert writes in a review of this post:
One thing I’ve ended up doing with live code upgrades, either in Erlang or at API/services level, is to design additional gradual steps, where you end up kind of working with both versions at once.
This is particularly useful (but costly) to do when maintaining state; you have the old version, running the old state. Then you have the new version, running with the new state. In-between, you have an intermediary version that runs the new code while maintaining an equivalent to the old state.
In a DB that’s often done by just double-writing in an old and new column at the same time (this may require 4 versions! 1. old, 2. future-ready, ignoring future columns but accepting them 3. double-write, 4. final), for as long as you need to ensure the correctness of the service is in fact untouched. Then you roll forward to the newer version and it acts like a checkpoint — that’s where you stop being able to roll-back.
Whatever your rollback or roll-forward strategy might be, it’s crucial to verify periodically that the mitigation is quick and indeed works as intended.
To Crash or Not To Crash
Often serving degraded responses or being able to operate in a degraded mode is a core design feature of distributed systems. Examples of such degraded mode of operations include: falling back to serving canned or cached responses when a database is unavailable, being able to operate when components used for performance optimization (such as caches) are unavailable, servicing reads but not writes (a newspaper website temporarily disabling comments but continuing to serve static content), and so forth. A twenty year old paper that proposes the notions of harvest and yield as a way of thinking about system availability (well, strictly speaking, the paper proposes the harvest and yield model as an alternative to the CAP principle; I personally see it not so much as an alternative than a corollary) provides a blueprint for thinking about tradeoffs.
However, when testing a small change in production, it might be preferable for the system under test to crash or fail outright, rather than linger around in a degraded mode. Microsoft published an interesting paper a couple years ago titled Gray Failure: The Achilles’ Heel of Cloud-Scale Systems, which argued that sometimes error recovery techniques exacerbate certain kinds of failures.
cloud practitioners are frequently challenged by gray failure: component failures whose manifestations are fairly subtle and thus defy quick and definitive detection. A more fundamental problem with masking gray failure instead of detecting it is that failed components may not get replaced, leading to their number eventually exceeding the number that can be tolerated.
Gray failure tends to exhibit an interesting evolution pattern along the temporal dimension: initially, the system experiences minor faults (latent failure) that it tends to suppress. Gradually, the system transits into a degraded mode (gray failure) that is externally visible but which the observer does not see. Eventually, the degradation may reach a point that takes the system down (complete failure), at which point the observer also realizes the problem. A typical example is a memory leak.
Fast feedback loops become very important when testing, and there’s no faster feedback loop than a service crashing loudly leaving behind enough diagnostics (a core dump, a crash log) to enable debugging.
However, services failing loudly by crashing is also fraught with its own risk. In July 2018, Google Cloud Global Loadbalancers experienced an outage that caused downtime for users of many GCP services, including Google Cloud App Engine.
Google’s Global Load Balancers are based on a two-tiered architecture of Google Front Ends (GFE). The first tier of GFEs answer requests as close to the user as possible to maximize performance during connection setup. These GFEs route requests to a second layer of GFEs located close to the service which the request makes use of. This type of architecture allows clients to have low latency connections anywhere in the world, while taking advantage of Google’s global network to serve requests to backends, regardless of in which region they are located.
The GFE development team was in the process of adding features to GFE to improve security and performance. These features had been introduced into the second layer GFE code base but not yet put into service. One of the features contained a bug which would cause the GFE to restart; this bug had not been detected in either of testing and initial rollout. At the beginning of the event, a configuration change in the production environment triggered the bug intermittently, which caused affected GFEs to repeatedly restart. Since restarts are not instantaneous, the available second layer GFE capacity was reduced. While some requests were correctly answered, other requests were interrupted (leading to connection resets) or denied due to a temporary lack of capacity while the GFEs were coming back online.
The phrase “this bug had not been detected in either of testing and initial rollout” seems a bit like a conterfactualism: that not enough code paths were tested was the conclusion drawn only because there was an outage. Testing, like monitoring, is akin to chasing a moving target. One can’t entirely predict how systems will fail; we can only approximate — and when systems do fail, they always do in surprising and unpredictable ways. Testing and monitoring are only as good as the understanding of the people authoring and operating the systems.
It’s also unclear based on this writeup whether the crash was caused due to the fact that a configuration change happened at the same time as a wide release of the code. It still remains that systems crashing when being tested in production can have unforeseen consequences.
One way to determine whether to crash or not to crash would be by categorizing services by criticality. An edge load balancer is a Tier 0 service. It’s arguably better for Tier 0 services to operate in a degraded mode than simply crash. A cache would be a Tier 1 service if unavailability of the cache impacted only the latency of the request but users could still be served responses. However, if the cache was also absorbing the worst-case load, then even momentary unavailability of the cache could cascade down to frontends, databases and backend services. Such a cache then becomes a Tier 0 service, and it’s probably better for it to degrade gracefully than crash loudly.
In very broad brushstrokes, it’s probably acceptable for a Tier 1 caching layer that’s being tested in production to crash and trigger an alert than continue to operate while ailing. Again, these are just hypothetical examples. To crash or not to crash when testing in production is a question that can be only be answered knowing the context, the problem domain, criticality of service and its dependency chain.
Change One Thing At A Time
This is generally good advice that has universal applicability. Testing in production introduces a change to the production environment; the people operating the service don’t have much of an inkling as to whether the test would succeed or fail. It becomes important not to couple this change with another change, be it change in some configuration option or changing the traffic patterns to the service or run some other test simultaneously.
Multi-tiered Isolation
An important action item of the GCP outage from 2018 linked above was the following:
We will also be pursuing additional isolation between different shards of GFE pools in order to reduce the scope of failures.
Services that share the same fate tend to fail in unison. Services share the same fate when they have a complex, strongly coupled dependency chain. By “dependency chain”, I mean not just the software dependencies, but also factors like:
- the environment in which the service is running
- the tooling that is used to operate the service (orchestrators that schedule or deschedule a service, agents that monitor a service, tools used for debugging a binary in production)
- any ancillary work a system needs to perform (such as submitting stats or logs to an agent, which strictly isn’t in the path of the request but is a salient part of operating and understanding a service)
- last but not the least, human operators
Yes, human operators as well, and in case you’re wondering why, I present exhibit A: a widespread AWS S3 outage from 2017.
At 9:37AM PST, an authorized S3 team member using an established playbook executed a command which was intended to remove a small number of servers for one of the S3 subsystems that is used by the S3 billing process. Unfortunately, one of the inputs to the command was entered incorrectly and a larger set of servers was removed than intended. The servers that were inadvertently removed supported two other S3 subsystems.
For an example of another such environmental “dependency”, I present exhibit B: the last major GCP outage from June 2019:
On Sunday 2 June, 2019, Google Cloud projects running services in multiple US regions experienced elevated packet loss as a result of network congestion for a duration of between 3 hours 19 minutes, and 4 hours 25 minutes. Two normally-benign misconfigurations, and a specific software bug, combined to initiate the outage: firstly, network control plane jobs and their supporting infrastructure in the impacted regions were configured to be stopped in the face of a maintenance event. Secondly, the multiple instances of cluster management software running the network control plane were marked as eligible for inclusion in a particular, relatively rare maintenance event type. Thirdly, the software initiating maintenance events had a specific bug, allowing it to deschedule multiple independent software clusters at once, crucially even if those clusters were in different physical locations.
The failure domain of systems with a complex dependency graph comprises of all the systems participating in the dependency chain. It then becomes required for each one of these services to be able to withstand the failure of all their transitive dependencies. In other words, this requires taking a very tightly coupled system and making it somewhat more loosely coupled, often at the expense of trading off either latency or correctness.
Loosely coupled dependencies benefit the most when there is physical and logical isolation of the individual components. Indeed, one of the action items of the aforementioned GCP outage was to improve isolation between different physical regions.
We have immediately halted the datacenter automation software which deschedules jobs in the face of maintenance events. We will re-enable this software only when we have ensured the appropriate safeguards are in place to avoid descheduling of jobs in multiple physical locations concurrently.
Physical isolation is relatively more straightforward since it mostly involves running multiple isolated copies of a given stack (where by “stack”, I mean the software and all of its “dependencies”). This can be achieved by setting up separate regions with multiple availability zones. Some cloud providers like AWS add an additional layer of compartmentalization in the form of cells, which can help protect against both regional failures and zonal failures. It’s important to ensure that isolation means isolation of both the control and the data plane. Global control planes (including automation tooling that can operate across the isolation boundaries) is a violation of the ethos of isolation.
Logical isolation is more nuanced as it deals with intra-service fault isolation. More concretely, services should be able to isolate along three crucial axes: bad inputs, upstreams and downstreams. And as it so happens, testing in production poses some unique challenges when it comes to each of these three cases.
Isolate Bad Inputs
When testing in production, one needs to work under the assumption that the inputs invariably will be bad. Treating the scenario of bad inputs as an edge case makes it more likely that this edge case is improperly handled or not handled at all.
In the best case scenario, bad inputs to a service or a bug introduced in the handling of inputs in code will cause the service to crash. This isn’t particularly problematic for a non-Tier 0 service, unless the change has been rolled out across the entire fleet of servers and all servers are now crash-looping, in which case there’s a full site outage. One architectural pattern for isolating bad inputs to Tier 0 services is the so called “poison taster” approach that AWS favors, where the input sanitization of customer provided input happens in an isolated system before it hits a high-criticality service. Having inputs of all requests being tested in production go through a “poison taster” can help detect bad inputs early on in the request lifecycle, before it can corrupt any state upstream. To quote Marc Brooker:
Correlation kills availability in distributed systems, because it removes all the benefit of having multiple copies. Applies to state just as much as code. Poison tasters help reduce the risk of common state causing correlated failure. A system with N-way redundancy with per-node failure probability f has availability approx 1-f^N, but as soon as those nodes suffer correlated failure, that drops to 1-f. Poison tasters help avoid that correlation.
In the worst case scenario, bad inputs to a service will cause the service to slow down or degrade in a subtle but pernicious manner. “Slow” is much, much harder to debug than an outright crash. This is in no small part due to the fact that error recovery in code is often designed for hard failure modes; “slow” is a latent failure mode that is uniquely hard to model and test. Left unaddressed, “slow” can wreck havoc with control flow and backpressure, escalate memory usage, and bubble up the stack through waves of failures that would have been more explicit had things failed fast.
Isolate Bad Downstreams
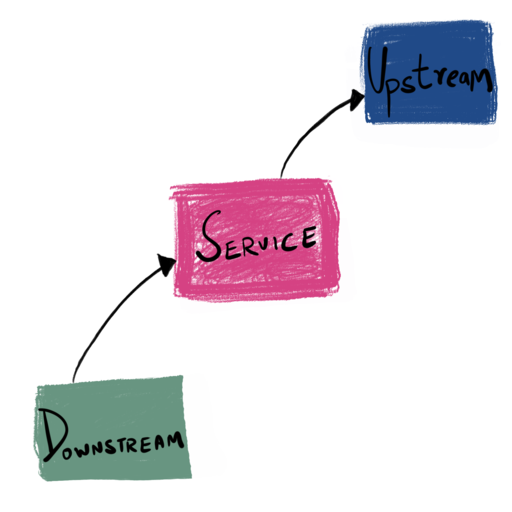
An “upstream” is a service that the service under test communicates with in order to perform some work. A “upstream” might either be another stateless service, or it could be something stateful like a database. A “downstream” is a service for which the service under test is an upstream.
If you’re going to be testing in production, you have to operate under the assumption that any request originating from the service under test is potentially a bad request. It then follows that the upstream needs to be able to identify and isolate requests originating from the service under test, flag the service under test if the initial set of requests prove to be problematic in some manner, and actively tarpit or reject subsequent requests from the service under test.
It’s impossible to talk about how an upstream can protect itself from a misbehaving downstream without talking about backpressure. Unless you’re serving identical requests arriving from the same client at all times at an identical rate, requiring identical amount of work in a completely static environment, every server is a multi-tenant system. It’s important when designing such multi-tenant services to be able to protect against misbehaving class of requests that trigger some form of degraded or pathological behavior, potentially affecting the response time of all other requests. In such cases, a “bad downstream” isn’t purely a bad downstream host or service, but an entire class of requests.
Services should be able to categorize the requests they receive in some form (by assigning a QoS, or by identifying the client, or identifying a request profile) and be able to protect itself from overload proactively.
Most talk about backpressure treats all requests as mostly identical. What is required to protect against a specific class of requests is per request-class backpressure. Requests that disrupt the steady state (SLO) must be penalized (outright rejected or put in low priority queues) more than requests that don’t. Some implementations achieve this by having multiple in-process queues, where different “types” of requests go into different queues, with the highest priority queues being processed (often in a LIFO manner), and lower priority requests being queued. When in-process queues are full, requests are outright rejected. Sufficiently jittered retries hitting an “upstream” aware load balancer that knows not to send a client request to a previously rejected backend can help even further.
Isolate Bad Upstreams
When testing a service in production, what constitutes a “bad upstream” becomes hard to detect. When observed from the vantage of a bad or buggy service under test, a “healthy” upstream might end up looking unhealthy. Accurate information from or about an upstream can be interpreted inaccurately by the service.
A good example here would be the case when a new change introduces blocking behavior to a service that’s supposed to be non-blocking. In such a case, the response time of a request to an upstream might “seem” unacceptably long when measured at the service. This information, if used in some form of end-to-end check or dynamic load balancing decision, can be interpreted as the smoking gun to classify the upstream as unhealthy, even if the problem really was with the service under test.
Thus, when testing in production, verifying that the information about the upstream is actually accurate requires comparing it with a known good baseline.
Divorce the Control Plane from the Data Plane
This post by Marc Brooker offers a good explanation on how to reason about the design of control and data planes. The control plane and the data plane typically have very different request patterns, operational characteristics and availability requirements. Generally speaking, data planes need to be highly available, even in the face of control plane unavailability whereas control planes need to favor correctness and security above all. Not having a clean separation between the data plane and the control plane often leads to fragile systems that are painful to debug, hard to scale and perhaps most importantly, hard to test.
This is made somewhat harder by the fact that what constitutes the control and data plane is often murky. Where the boundary lies is very much domain specific. Broadly speaking, control planes and data planes aren’t physically colocated (except sometimes, they are). Data planes are typically more amenable towards staged rollouts. The blast radius of control plane malfunction is every single data plane it is responsible for. Control planes can have control planes that configure them. In the image below, C1 is a control plane, that configures C2, C3 and C4. From C1’s perspective, its data planes are C2, C3 and C4. However, C2, C3 and C4 themselves are control planes that configure the data planes D1, D2 and D3 respectively.
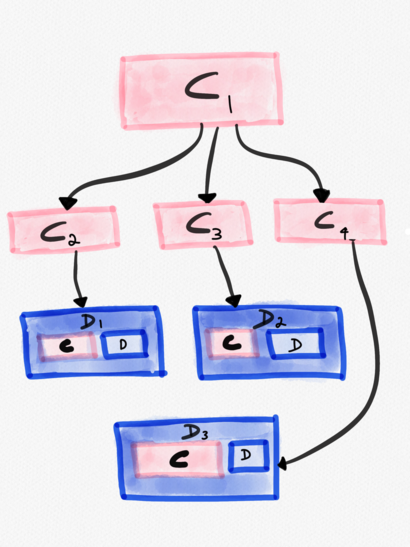
For example, if you are running Kubernetes and have bought into the “small clusters, lots of them” mantra, then each of these small clusters is going to require a control plane. Managing multiple control planes then makes it necessary to have a top-level control plane that configures each of these control planes. A more concrete example of a such a “control plane of control planes” can be found in Facebook’s cluster scheduler, Tupperware, which in theory, offers a single, shared control plane abstraction.
A single control plane managing servers across data centers to help automate intent-based container deployment, cluster decommission, and maintenance. The abstraction of a single control plane per region greatly improves usability for job owners and provides easier manageability of a large shared fleet. Note that the control plane can maintain the abstraction of a single point of entry even if scale or fault-tolerance concerns lead to the control plane being sharded internally.
Likewise, data planes can be further decomposed into a meta control plane component and a meta data plane component. There exists functionality in a data plane that is executed out of band and isn’t directly in the path of every single request. A good example here is active health checking of upstreams — which might typically happen on a timer and the result cached until the next health check detects a change in status. In the case of “push based health checks” (setting a Consul or Zookeeper watch might be an example here), the health status is updated asynchronously only when there’s any change to the key being watched. Another example of “data plane” activity that happens out of band of request processing would be how a service chooses to report its health to its downstream. Some services implement backpressure by reporting their health based on factors like internal queue lengths, amount of disk space available, CPU utilization of the container, number of actively connected clients and more. Monitoring of disk space in the background often happens asynchronously on a timer and isn’t in the path of a request. Yet another example would be how a service, once it gets unhealthy or is TERMed, chooses to drain traffic before exiting (also known as “graceful shutdowns”). A service going into drain mode is a one time occurrence that happens independent of client requests. These are “control plane” components, even within a data plane. Maintaining a clean separation in code leads to better abstracted code that’s often orders of magnitude easier to test and debug.
Eschew Global Synchronized State
Shared mutable state in code is often considered to be the root of all evil. The same can be said when it comes to systems — global state mutations, especially of control plane data, is something to be actively eschewed for the simple reason that the blast radius of such a system encompasses all services that depend on this state. To cite this excellent Netflix blogpost about why distributed mutable state is a last resort in the context of load balancers:
We generally employ distributed mutable state only as a last resort, as the value gained needs to outweigh the substantial costs involved:
— Operational overhead and complexity it adds to tasks like deployments and canarying.
— Resiliency risks related to the blast radius of data corruptions (ie. bad data on 1% of load balancers is an annoyance, bad data on 100% of them is an outage).
— The cost of either implementing a P2P distributed state system between the load balancers, or the cost of operating a separate database with the performance and resiliency credentials needed to handle this massive read and write traffic.
Barring some very notable exceptions, there’s almost always an alternative architecture where the reliability of a system can be improved by rearchitecting components that rely on metadata that needs to be globally synchronized. And in the rare instances when a global synchronization is unavoidable, it’s essential that the control plane responsible for performing this synchronization is:
- slim, so it’s only concerned with doing one thing really well
- ideally entirely stateless, with the minimal number of dependencies
- if stateful, doesn’t require strong consistency guarantees or write quorums
- persists snapshots of a known good state, so if it’s required to rebuild its state, it can synchronize just the delta from the source of truth.
- ideally self-healing
- well monitored
- must crash “safely”
Let’s look at a more concrete example of how this can be achieved. I previously worked at imgix, a real-time image transformation service. imgix was a complex distributed system. Users set up a source via the dashboard, where a source roughly translated to information regarding the customer origin (S3, GCS etc) and configuration that needed to be applied to every image transformation (like the TTL of the derivative image, the “error image” that required to be served should the requested image not be present in the origin server, and more). Users updated this configuration via the dashboard and expected this data to take effect almost instantaneously. For this change to take effect, it needed to be pushed out to three crucial systems, one of which was all of the edge load balancers which intercepted all ingress traffic. In essence, we’re talking about globally synchronized state. CDNs which distribute configuration globally have similar requirements.
The following diagram depicts such an architecture.
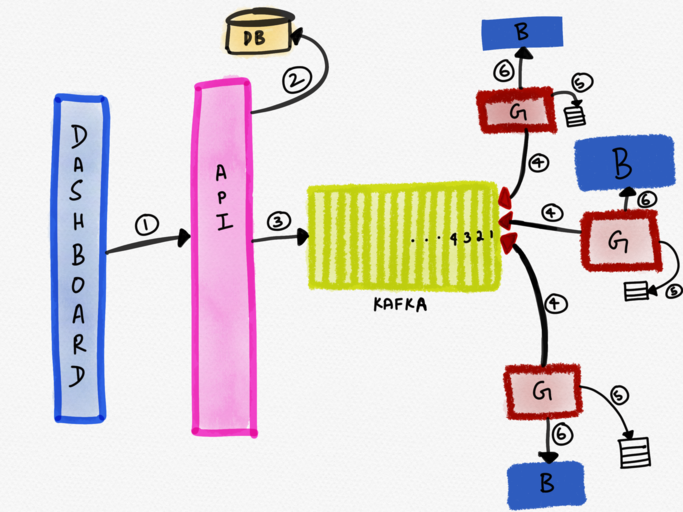
The dashboard wrote the change to the database via an API (1), which then published this update to Kafka (2). Kafka was used as a distributed message broker, not so much as a “streaming engine” since Kafka provided exactly the guarantees we needed, viz., asynchronous coupling and ordered delivery of messages to multiple control planes.
The control plane (let’s call this service G) ran on every edge load balancer host and consumed updates off Kafka (4). These updates were written to a file (5), and the update was then applied to the data plane (via a reload of HAProxy). It’s interesting to note here that the control plane was colocated with the data plane it was configuring.
Service G met all of the requirements listed above:
1. slim — this component was very thin and its only responsibility was consuming messages off Kafka and reloading the configuration of HAProxy (the edge load balancer).
2. stateless with no dependencies — this system didn’t persist any state (other than a file on disk used for diagnosis). It was had no downstreams and only had one upstream dependency (the API server used in the error recovery scenario).
3. didn’t require strong consistency guarantees — It was important all consumers of the data converged on the configuration updates; however, we didn’t strictly require very strong consistency guarantees here. The problem we needed to solve was one of convergence and have an SLO for convergence lag.
4. maintained known good states — this system, as stated above, stored a versioned map of the configurations on the filesystem.
5. self-healing — this system was intelligent enough to know when it’d missed an update and fetch the delta. Every message published to Kafka had a monotonically incrementing globally unique ID associated with it. The control plane tracked the ID of the last update it received. If the ID of the last update was, say, 10 and the newly consumed message had an ID of 12, the control plane knew that it’d missed an update and would sync the delta from its only upstream — the API server (step 5 in the illustration below).
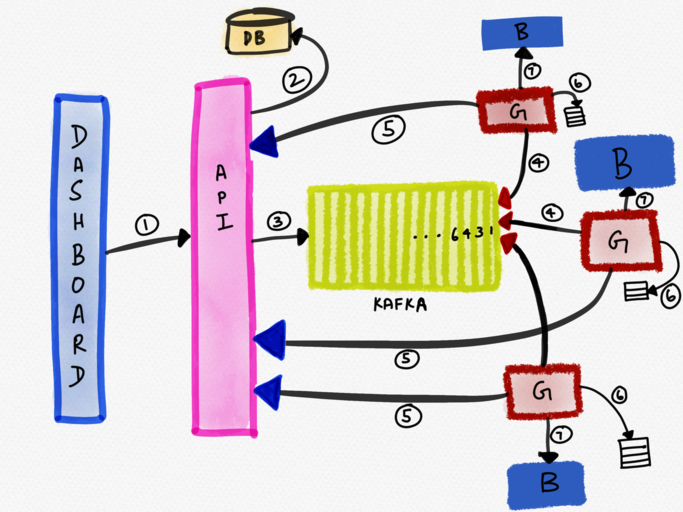
6. well-monitored — In addition to an end to end test that updated the configuration of a source periodically and alerted if the configuration hadn’t propagated to all systems, we had additional monitoring to ensure that the data plane always had the most recent configuration.
7. must crash “safely” — If service G missed an update or crashed, older configurations would be effective at the data plane. Inability to propagate an update didn’t mean the system would stop functioning. Additionally, the co-located data plane could serve requests based on local (outdated) information even in the event of a control plane failure.
Points 4 and 6 above are arguably the most important here. A fair number of outages of control planes have been traced down to the fact that they weren’t designed to be able to recover soon enough in the event of a failure. One of the action items of Google’s last major outage from June 2019 was the following:
Furthermore, the network control plane in any single location will be modified to persist its configuration so that the configuration does not need to be rebuilt and redistributed in the event of all jobs being descheduled. This will reduce recovery time by an order of magnitude.
Another design used in certain AWS systems is one called “constant work”, where the control planes pushes all of the updates all the time to the data planes. The talk titled Load Balancing at Hyperscale by Alan Halachmi and Colm MacCarthaigh at the Networking @Scale conference sheds more light about this approach where there’s no “delta” to synchronize — the entire source of truth is being propagated to the data plane as an atomic unit continually. The talk doesn’t go into much detail about how recovery works in the event of incorrect data being pushed out to all the data planes or if the data planes hold on to multiple versions of the configuration data and have any fallback mechnism built in, but I still found it a fascinating approach.
Other Considerations
There are certain additional considerations that don’t strictly impact blast radius but are salient that are of salience when it comes to testing in production.
Client Resilience and Client-Side Metrics
Testing server side software in production requires some degree of cooperation from the client, where a “client” might be the browser, a mobile app, the “edge” (CDNs) or a downstream server. If the test in question is verifying latency of the test request is within a certain threshold, measuring this client-side makes most sense. If the test is verifying that utilization or throughput is within acceptable bounds, then measuring this server-side makes most sense.
If both the client and the server are owned by the same team, measuring at both places while testing in production becomes somewhat easy. If the client-side software is owned by a different team (as is often the case in a microservices architecture), then testing either system in production poses technical and social challenges.
On the technical front, clients might not publicly expose enough telemetry to be able to validate server-side software. Client-side resilience initiatives (such as adding jitter and exponential backoff to retries) are required to be in place to paper over any potential server-side degradation (such as overload of the new server side code being tested in prod).
On the social front, testing server or client side code in production requires at the very least informing the other team of the intention to run such a test. Not all teams might share the same appetite for risk (or for that matter, the same employer). Some teams might’ve burned through their error budget and might not might be amenable to the possibility of further potential hiccups. Client side metrics might be ACL’d and not visible to the server side team.
Having access to client-side metrics becomes even more important when the measurement happens client-side as in the case of “sticky canaries”, where requests (including retries) from a single client is always sent to the same canary instance. It’s tantamount to pinning a small population of clients to the canary instance, and sending 100% of these clients’ traffic to the canary. This enables the collection of enough signal to detect certain class of errors caused by server side changes observed only in the client. Extracting this signal meaningfully requires that errors not be masked by client retries that could end up being serviced by a non-canary instance. As Haley Tucker put it:
The main benefit is finding customer impact which happens later in an app lifecycle due to a bad response from the service under test. We can actually monitor the client metrics the business cares about to know if a change will cause users harm. The trick is detecting it very quickly and shutting it down so users aren’t stuck in that mode for too long.
Testing in production without consummate visibility into client side performance is probably a very bad idea, and access to client side metrics at the level of granularity desired isn’t something that can necessarily be taken for granted.
Invest in Observability
It’s impossible to be able to effectively test in production without a rock-solid observability pipeline. Observability signals help surface outliers, visualize the impact and scope of the change and help in alerting when a test run in production produces an unexpected output.
What’s of the essence here is that the observability tool is tenancy and origin aware. Tenancy is a measure of how many types of workloads a cluster is configured to serve. Mixed-mode tenancy clusters, for instance, serve both production and test requests. Origin is the counterpart of tenancy and helps answer if a request was user-originated or test-originated.
Grey failures are the Achilles heel of testing in production. It becomes impossible to diagnose such failures without a tool that supports dimensionality at the very least. Ideally, you’d also want a tool that can support high-cardinality that’ll enable an engineer to slice and dice across any dimension in order to quickly and cheaply validate hypothesis, which becomes a precursor to understanding the nature and nuances of failure.
Conclusion
I’ve grown to believe that “testing in production” is a bit of a misnomer. “Testing production” or “verifying production” seems more apt a description. Users are interacting with the production environment at all times, so in a manner of speaking, production is already constantly being exercised.
If after reading this post, your instinct is that “testing in production is too hard”, then do bear in mind that we haven’t covered stateful services. Testing stateful services in production opens an entire new can of worms in its own right and will be covered in a follow-up post.
Testing in production can be difficult to get started with, and it’s taken companies that successfully test in production years to reach the level of sophistication and maturity to perform such tests safely and rapidly. In the seminal paper titled Maelstrom: Mitigating Datacenter-level Disasters by Draining Interdependent Traffic Safely and Efficiently, Facebook notes:
It has taken us multiple years to reach our current state of safety and efficiency. Our original tests only targeted one stateless system: our web servers. The first set of drain tests were painful — they took more than 10 hours, and experienced numerous interruptions as we uncovered dependencies or triggered failures that resulted in service-level issues. As we built Maelstrom and began using it to track dependencies, drain tests gradually became smooth and efficient. After a year, we extended drain tests to two more services: a photo sharing service and a real-time messaging service. Currently, Maelstrom drains hundreds of services in a fully automated manner, with new systems being onboarded regularly. We can drain all user-facing traffic, across multiple product families, from any datacenter in less than 40 minutes.
Getting started with testing in production can in and of itself prove to be extremely valuable, since it works as a forcing function to make engineers proactively think about blast radius, fault isolation, graceful degradation, restoration of service, automation, better observability tooling and much more.
Modern day services are getting increasingly more complex to design, author, test, operate, debug and maintain reliably. Taming this complexity requires systems designed to tolerate a whole class of failures; “testing in production” is merely the continuous and ongoing verification that the system does indeed function as designed.
