Effective Mental Models for Code and Systems
As always, I’m greatly indebted to Fred Hebert for reviewing a draft of this post and offering some invaluable insights.
A little over a month ago, Carmen Andoh gave a talk at a meetup in Copenhagen about visualizations, though it really was a talk on mental models. In her talk, Carmen described a mental model as:
A mental model is an explanation of someone’s thought process about how something works in the real world. It is a representation of the surrounding world, the relationships between its various parts and a person’s intuitive perception about his or her own acts and their consequences.
Carmen also drew attention to what Rob Pike had once said about Ken Thompson’s preferred approach to debugging:
A year or two after I’d joined the Labs, I was pair programming with Ken Thompson on an on-the-fly compiler for a little interactive graphics language designed by Gerard Holzmann. I was the faster typist, so I was at the keyboard and Ken was standing behind me as we programmed. We were working fast, and things broke, often visibly — it was a graphics language, after all. When something went wrong, I’d reflexively start to dig in to the problem, examining stack traces, sticking in print statements, invoking a debugger, and so on. But Ken would just stand and think, ignoring me and the code we’d just written. After a while I noticed a pattern: Ken would often understand the problem before I would, and would suddenly announce, “I know what’s wrong.” He was usually correct. I realized that Ken was building a mental model of the code and when something broke it was an error in the model. By thinking about *how* that problem could happen, he’d intuit where the model was wrong or where our code must not be satisfying the model.
Ken taught me that thinking before debugging is extremely important. If you dive into the bug, you tend to fix the local issue in the code, but if you think about the bug first, how the bug came to be, you often find and correct a higher-level problem in the code that will improve the design and prevent further bugs.
I recognize this is largely a matter of style. Some people insist on line-by-line tool-driven debugging for everything. But I now believe that thinking — without looking at the code — is the best debugging tool of all, because it leads to better software.
Even if one doesn’t entirely subscribe to this school of thought, being able to build, validate and communicate one’s mental model of a problem is extremely powerful, especially so since mental models, even the best ones, are ephemeral. Even the same person’s mental model of a piece of code or system might not be the same across distinct points in time.
Code is a social construct. It comes into existence as an attempt to create an imprint of an ephemeral mental model of the group of engineers involved in its original design and implementation. Code is an artifact of a team’s possibly incomplete, possibly flawed and possibly ambiguous understanding of a problem and as such is possibly an embodiment of all of these shortcomings. Tests written in support of a given piece of code share the same fate.
Modification of code comes with the risk of subtle invalidation or inadvertent distortion of the initial assumptions under which it was written. Rinse and repeat, and after a certain amount of time one is left with a codebase that is a patchwork of various mental models overlaid on top of each other that no one engineer fully understands or can reason about accurately. This results in an increase in complexity of the codebase as a whole.
In the excellent book A Philosophy of Software Design, John Ousterhout writes:
Complexity isn’t caused by a single catastrophic error; it accumulates in lots of small chunks. A single dependency or obscurity, by itself, is unlikely to affect significantly the maintainability of a software system. Complexity comes about because hundreds or thousands of small dependencies and obscurities build up over time. Eventually, there are so many of these small issues that every possible change to the system is affected by several of them.
The incremental nature of complexity makes it hard to control. It’s easy to convince yourself that a little bit of complexity introduced by your current change is no big deal. However, if every developer takes this approach for every change, complexity accumulates rapidly. Once complexity has accumulated, it is hard to eliminate, since fixing a single dependency or obscurity will not, by itself, make a big difference.
This is an inevitability for large codebases worked on by a large number of developers as more and more code gets added to the codebase or when the codebase is modified . The problem is exacerbated when it comes to systems, since we’re now dealing with not just code but a variety of systems authored and run by different teams (or even organizations) where the mental models under which these systems are built and operated aren’t validated or communicated as thoroughly as would be ideally welcome.
Fortunately, for us, this isn’t all doom and gloom. As John Allspaw writes in an incredibly insightful recent article titled “Recalibrating Mental Models Through Design of Chaos Experiments”:
An important finding in Woods’ recent research of cognitive work in software engineering and operations environments is that a primary way engineers cope with this complexity is by developing mental models of how their software systems behave in different situations (normal, abnormal, and varying states in between). These mental models are never accurate, comprehensive, or complete, and different individuals have potentially overlapping but different models of the same areas of their systems.
The inaccuracy or incompleteness of these various mental models generally (and perhaps surprisingly) does not cause significant problems. Multiple people (even those on the same team!) can hold these differing and incorrect understandings of how their systems behave for some period of time without much consequence, and without any awareness that these understandings contrast.
A programmer modifying the code doesn’t have to arrive at the exact same mental model under which the code was written; they only need to arrive at a close enough approximation of it. A quintessential example of this is “the relativity of wrong” proposed by Isaac Asimov, which uses different wrong models for the curvature of the earth (the earth is flat, spherical, oblate spheroid) to demonstrate how this does not necessarily prevent everyday uses of the model. The model becomes “wrong” only when an invariant is changed.
That said, I do believe that there are some guidelines which, if followed at the time of authoring code, can help ease the cognitive load on a future reader and gently guide them toward arriving at such an approximation of the mental model under which it was authored.
Optimize for Understandability
If I were to draw a hierarchy of needs but for codebases, I’d put understandability at the very bottom of the pyramid.
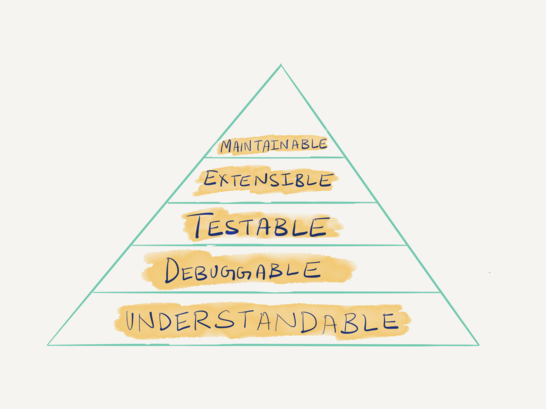
Understandability is one of the most basic needs of readers of a piece of code. Optimizing for understandability can result in optimizing for everything else on the hierarchy depicted above. Understandable code is code that lends itself well towards being debugged. Code can often be debugged with a test case. Code that’s easy to test is, as often as not, code that’s modular and extensible. Modular and extensible code is also code that’s generally maintainable.
It’s important to note here that this just doesn’t apply to code. It applies equally to systems, though in the case of systems, the yardstick of how understandable a system is tends to be how observable it is.
Identify all the different target audience
A critical factor to optimizing for understandability is having a well-defined target audience for the code that’s being authored. A single codebase may consist of multiple components (libraries, binaries, configuration files and so forth) each of which might cater to a different target audience. Not thinking about the (possibly opposing) needs of the various target audience can result in awkward to use APIs.
In the case of libraries, the target audience comprises of all the different potential clients of the library. For something like a standard library of a language, the target audience comprises of the entire developer community. For a library that purely concerns itself with a certain business logic functionality, the target audience might comprise of other developers on the team or in the organization.
For the kind of code I write, there’s also an operator experience I need to be cognizant of, which dictates its ease of use for someone responsible for its operation; in some cases the operators might be SREs, in other cases, the operators might be the software engineers authoring the code.
In general, when identifying the target audience and deciding what narrative to expose to them in order to allow them to get up and running quickly, it becomes necessary to consider the audience’s background, level of domain expertise and experience. As often as not, the target audience might very well comprise of novices as well as veterans. In such cases, the litmus test for the understandability of the code is determined by the experience of the novice. When dealing with a specific target audience, it is essential that the APIs they are exposed present a vocabulary that feels natural to them, even if that might not necessarily be the semantics the implementors might be the most comfortable with (having internal and external APIs in such cases can provide much relief).
Self-documenting code is a myth
Much has been written about the pros and cons of self-documenting code. In my experience, the problem with code that’s self-documenting is that it doesn’t allow for the dissemination of the context under which the code was written. Code is the end result of a team understanding a problem, communicating with users, and working towards an artifact that’s something of a compromise between various competing constraints and requirements. The code itself lets a reader know what decisions were made, but not why.
Moreover, there’s only so much one can capture with code; trying to shoehorn every last bit of context in code leads to the code looking clunky and hard to understand (think of code with very lengthy and unintuitive variable or function names, numerous layers of gratuitous indirection or ideas being represented by fractured fragments of code that never truly come together to reconstruct the original idea in its entirety).
While code is not a design document, it helps when reading code to be privy to some of the context. This is especially true when a certain piece of code is written a certain way for performance reasons or when code was refactored to make it more extensible or when the initial implementation had known shortcomings or was written under time and budget constraints and fluid requirements. This context is extremely valuable to a future reader of the code to understand the milieu in which the code was born and why it exists the way it does, which then paves the way toward the future reader making informed choices about how the code can be best evolved.
Comments are easier to parse than code
Proponents of self-documenting code also champion not including any comments in code. Code that attempts to be self-documenting is code that starts to read like prose. I find it easier to read code when it looks like code — which is to say, I like short expressions, short function names, and easy to process code.
Having to build up a mental model (let alone anything even remotely close to the one which governed the existing implementation) from scratch with only pure code to help one along the way isn’t a very good user experience for someone new to the codebase. Comments furnish my mental model with the context in which the code was written— the interface, so to speak. It tells me “what and why”. Code is the implementation — it tells me “how”. Comments and code are complementary in the best of cases. The best comments are those which make the implementation (code) a lot easier to understand.
A Case for Better Composition of Layers
Well-designed codebases are often composed in layers and subsystems, with each layer providing as close to hermetic an abstraction as possible (as impossible as it might seem) while exposing a simple interface to its users.
However, while designing layers, it’s also important to note that the composition of these layers can significantly shape the understandability of the codebase as a whole. The decomposition of software into layers should be a reflection of the fact that the most powerful mental models are intuitive and modular, hierarchical yet amenable to a breadth-first exploration.
For instance, most developers find synchronous APIs a lot easier to use than asynchronous APIs. Synchronous APIs present a temporal interface to the user, which is intuitive and easy to reason about. Languages like Go succeed in encapsulating the underlying asynchrony in the language’s runtime, offering the end user a very simple API to program against. “Line of sight” code, likewise, is much easier to understand.
It’s also crucial that layers be explorable in a breadth-first fashion, with the programmer hopefully only having to do a shallow search to become familiar with the higher-level APIs. This enables them to begin using the higher-level APIs effectively forthwith which can make them productive sooner. The only reason a reader should have to get into the weeds of the implementation would be when they need to change the underlying implementation.
Each layer should encapsulate an “Error Kernel”
In his talk The Do’s and Don’ts of Error Handling, Joe Armstrong posits that “large assemblies of small things are impossible to prove correct”, and that when it comes to large systems, it becomes important to be able to identify and isolate the error kernel of a system.
We should identify the error kernel. The error kernel of a system is that part which must be correct. That’s what the error kernel is. All the other code can be incorrect, it doesn’t matter. The error kernel is the part of the system that must be correct. If it’s incorrect, then all bets are off. The error kernel must be correct.
For a system dealing with purely business logic (let’s say, payments or booking a flight), the error kernel is the business logic in question. For a network proxy, the error kernel comprises of the code that deals with network level failures.
While designing software layers, it’s salient that every layer encapsulate an error kernel. As a user of a layer, it’s important that I be offered an API that abstracts away most of the complexity of the implementation during the happy path.
However, the best layers are those which, at the time of in-situ debugging, make it relatively easy for a user of the layer to figure out how their usage of its API violated the layer’s error kernel, thereby resulting in unexpected or surprising behavior.
Designing the kind of layers that offer the dual properties of “lean and simple during the happy path” and “ergonomic and amenable to comprehensive exploration at the time of debugging” allows the users of the layer to mostly be oblivious of the error kernel, but should the need arise (as it almost invariably will owing to abstractions being leaky), have the tools at their disposal to build the right mental model to manoeuvre the depths of the implementation to uncover the cause of the bug.
Do not omit details owing to “shared understanding”
Sometimes, there are certain members of a team who have a shared understanding of a certain part of a codebase or a system. This can be due to a variety of reasons. It could be because these team members have been on the team for much longer than others or because they possess a particular domain expertise. It could also be because the codebase is so sprawling that not everyone on the team is equally up to speed with every part of it. At certain companies, there are people designated as “code owners” and all changes to the code they “own” is required to be approved by them.
Provided the higher level interfaces of the code “owned” by certain people are simple to understand and easy to use, I’m not opposed to the notion of having code owners. Sometimes it’s an inevitability that some people on a team will end up having more familiarity with certain parts of the codebase than others. However, it’s imperative that this not be used as a license to leave the tribal context tacit.
What’s “shared understanding” to some is “hidden knowledge” to others, and can turn into an “unknown-unknown” for new readers of the code. It takes a certain amount of time and effort for the original implementor of a piece of code to construct the mental model under which it was authored, and if left undocumented, not only is the next programmer who touches the code going to have to spend the same (if not more) effort in trying to understand how it works, they also risk leaving with an understanding of it they think is complete, but not realizing that the essentials have been inadvertently withheld from them. This can prove to be cataclysmic when it pertains to the aforementioned error kernel.
Furthermore, as already mentioned in this post, it’s truly rare that even those with a “shared understanding” of a piece of code or a system will have the selfsame mental model of it. Documenting knowledge which is assumed to be shared and thus deemed “implicit” can help unearth surprising nuances and details about “shared perceptions” that might’ve perhaps been initially shared but have been ultimately lost to the sands of time. Erring on the side of over-communication in code has never once gone amiss in my experience.
Make implicit assumptions and dependencies explicit
Speaking of implicit knowledge, it is worth reiterating this again that implicit assumptions and dependencies are one of the worst offenders when it comes to contributing to the obscurity of code.
In fact, I’d go so far as to argue that the pieces of information and knowledge that seem obvious to a programmer at the time of writing code are the most susceptible to being deemed redundant to document, and thereby the most susceptible to ending up being implicit (and by extension, invisible).
Invisible dependencies or assumptions can lead to myriad problems down the road. For a start, the codebase can end up becoming inscrutable. Secondly, any potential future change made without a vital piece of invisible information can end up having unexpected side-effects or even subtly invalidate the behavior of the code. In the most pernicious of cases, this sort of regression isn’t caught by the existing test suite, and only ever becomes obvious after an episode of painful debugging of a cryptic production issue.
Concrete is better than Abstract
When trying to form a mental model of something, it always helps me to latch onto something concrete first. When writing code or designing layers, it’d greatly help to think how to offer something concrete to a new user. This could either be an example usage of the code or an explanation of when a certain behavior might take effect or what a certain pathological use case for a module might be.
An example would be when trying to learn a new API or standard library function, I tend to be able to use it a lot sooner if I were presented with a concrete usage of the API, as opposed to presenting me with just the signature. If I am only presented with a signature, then it had better come with sane defaults, in particular when the API in question pertains to a domain I’m unfamiliar with or a programming language I’m new to.
Validation to Compare, Contrast and Recalibrate Mental Models
Quoting from the article “Recalibrating Mental Models Through Design of Chaos Experiments” again:
Real and successful work critically depends on the continual recalibration of mental models that people have of the systems they are responsible for. These mental models are always being updated with new understanding of the system’s configuration, dependencies, and behaviors under a huge variety of conditions.
Chaos engineering is but one form of validation that can result in the recalibration of mental models. Other forms of validation that greatly help with recalibration at the code and algorithmic level include formal specification, property based testing and fuzzing.
I‘ve written extensively in the past about verification and debugging of systems, but a lot of the potential still remains untapped due to the absence of intuitive and ergonomic interfaces that can chaperone users toward forming and validating hypotheses.
While designing interfaces, it’s important to think of the different target audience of the system and understand that each of them might require a custom interface tailored to their needs. Overwhelming all the users with all of the information about a system at all possible times is a terrible anti-pattern and actively inhibits a user’s ability to form a mental model of the working or dysfunction of a system. In such cases, the results are only interpretable if a user knows what to look for, which is contingent on the assumption that they already have a working mental model of what they’re trying to debug in their mind, when this is rarely the case. Instead, modeling the exploratory process as a series of questions and answers the user can easily walk through offers a vastly better user experience in their quest to compare and recalibrate their mental models.
Conclusion
A recent New Yorker profile on Google’s famed duo Jeff Dean and Sanjay Ghemawat features a paragraph on Barbara Liskov’s views on programming:
His graduate adviser was Barbara Liskov, an influential computer scientist who studied, among other things, the management of complex code bases. In her view, the best code is like a good piece of writing. It needs a carefully realized structure; every word should do work. Programming this way requires empathy with readers. It also means seeing code not just as a means to an end but as an artifact in itself. “The thing I think he is best at is designing systems,” Craig Silverstein said. “If you’re just looking at a file of code Sanjay wrote, it’s beautiful in the way that a well-proportioned sculpture is beautiful.”
“Some people,” Silverstein said, “their code’s too loose. One screen of code has very little information on it. You’re always scrolling back and forth to figure out what’s going on.” Others write code that’s too dense: “You look at it, you’re, like, ‘Ugh. I’m not looking forward to reading this.’ Sanjay has somehow split the middle. You look at his code and you’re, like, ‘O.K., I can figure this out,’ and, still, you get a lot on a single page.” Silverstein continued, “Whenever I want to add new functionality to Sanjay’s code, it seems like the hooks are already there. I feel like Salieri. I understand the greatness. I don’t understand how it’s done.”
The quality of code is judged not by its initial authors but by the future readers and debuggers of the code, since the onus to reconstruct the mental model under which the code was authored falls squarely on the reader of the code.
Empathy for the future reader requires the current implementors invest the time upfront to map out the whys and the wherefores of circumstances which influenced the implementation, in addition to having a certain amount of foresight into possible future limitations of the current implementation (which in turn requires them being aware of the pros and cons of the tradeoffs being currently made). Not doing so leaves the future reader with no empirical data to base their mental model on, leaving them with no choice but to either resort to guesswork to fill this void or simply soldier on knowingly missing vital pieces of information.
Reducing the cognitive load on the future reader and helping them build a better mental model of our code minimizes the risk of the introduction of bugs, unlocking the ability for a future generation of maintainers to make progress at a rapid clip. It also helps build a culture of paying it forward with respect to managing complexity, effectively amortizing the maintenance cost of the codebase over time.
